DataOps a automatizace datových pipeline
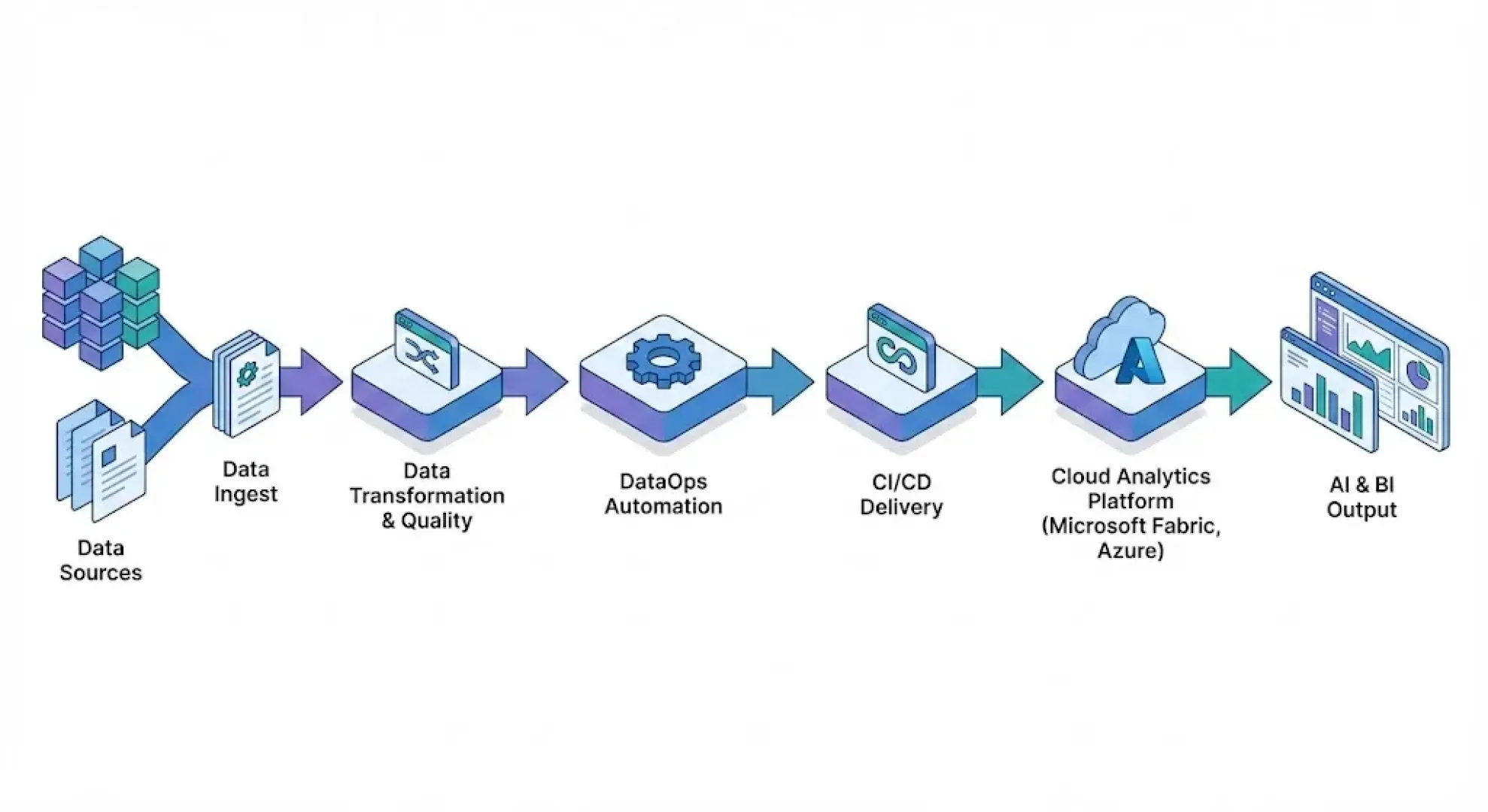
DataOps je přístup, který přenáší osvědčené principy DevOps a agilního řízení do datové oblasti. Jeho cílem je zrychlit dodávku datových výstupů a současně zvýšit jejich spolehlivost – díky standardizaci, automatizaci a měřitelnému řízení kvality. V praxi DataOps sbližuje datové inženýry, analytiky, datové vědce a IT provoz tak, aby datové pipeline vznikaly a běžely stejně disciplinovaně jako moderní software.
Principy DataOps a návaznost na DevOps
Stejně jako DevOps stojí na CI/CD, verzování kódu a automatizovaném testování, DataOps aplikuje tyto koncepty na datové transformace, datové modely a orchestrace pipeline. Každá změna (např. úprava transformační logiky, schématu tabulek nebo pravidel kvality) je verzována v Gitu, prochází kontrolou a testy a teprve poté je nasazena do vyšších prostředí. Důležitou součástí je „infrastruktura jako kód“ – prostředí a konfigurace se definují opakovatelně a auditovatelně, což snižuje riziko ručních zásahů v produkci.
DataOps zároveň posiluje společnou odpovědnost za end-to-end tok dat. Z hlediska managementu to znamená předvídatelnější doručování změn, menší počet incidentů a jasnou stopu toho, co se v datové platformě měnilo a proč.
Automatizace pipeline od sběru po nasazení
Jádrem DataOps je automatizovaný „assembly line“ pro data. Pipeline typicky pokrývá ingest (načtení dat), transformace, validace kvality, publikaci do cílových vrstev a nasazení datových produktů (např. tabulek pro reporting, datasetů pro Power BI, případně features pro ML).
Klíčové jsou automatizované kontroly kvality: validační pravidla (schéma, rozsahy, referenční integrita, úplnost) běží průběžně a při odchylkách spouštějí alerting, karanténu dat nebo definovaný opravný postup. Tento „quality gate“ chrání byznys před tím, aby se do reportingu či modelů dostala chybná data.
Nasazování změn probíhá řízeně přes CI/CD: od vývoje v izolovaném prostředí, přes testy a schválení, až po produkci. Díky tomu lze doručovat menší změny častěji, bez rizikových „velkých release“.
Přínosy pro byznys
DataOps přináší čtyři praktické dopady:
- Rychlost: kratší čas od požadavku k datovému výstupu, možnost iterovat týdně i denně.
- Spolehlivost: méně chyb díky automatizaci, testům a standardům; rychlejší detekce a řešení incidentů.
- Auditovatelnost: jasná historie změn, dohledatelnost verzí pipeline i dat, lepší kontrola a governance.
- Znovupoužitelnost: sdílené komponenty a šablony (konektory, transformace, validační pravidla) snižují náklady a zrychlují nové use-cases.
Microsoft a Azure jako DataOps ekosystém
Azure poskytuje ucelený set služeb pro DataOps napříč datovým životním cyklem. Pro orchestraci datových toků se často využívá Azure Data Factory (resp. integrační schopnosti v rámci Microsoft Fabric), které umožňují řízení pipeline, plánování běhů, parametrizaci i monitoring. V kombinaci s lakehouse přístupem (Microsoft Fabric/OneLake) a otevřenými formáty typu Delta lze budovat robustní vrstvy dat (bronze/silver/gold) s konzistencí a možností verzování.
Pro ukládání a publikaci dat se typicky používají služby jako Azure SQL a další analytické vrstvy dle potřeb (např. warehouse/lakehouse). Event-driven automatizaci a integraci doplňují Azure Functions či Logic Apps. Pro řízení vývoje, verzování a release je přirozenou volbou Azure DevOps (Repo, Pipelines) případně GitHub, kde lze nastavit CI/CD pro infrastrukturu i datové komponenty.
Výsledkem je platforma, kde lze standardizovat procesy od vývoje přes testování až po provoz – a měřit je pomocí metrik dostupnosti, latence zpracování, počtu incidentů a kvality dat.
Jak Data Mind pomáhá
Data Mind pomáhá klientům zavádět DataOps pragmaticky: od návrhu architektury na Microsoft/Azure stacku přes nastavení CI/CD, validačních pravidel a monitoringu až po předání standardů týmům, které řešení provozují. Cílem je dostat datové pipeline pod stejnou kontrolu a disciplínu jako kritický software – aby se data stala rychlým, spolehlivým a dlouhodobě udržitelným základem pro reporting, pokročilou analytiku i AI.